

Blueprints for Advanced CustomGPTs & Claude Projects: The Operator’s Guide
Master production-ready CustomGPT architecture from brainstorm to self-improving meta-instructions. Use the 10-point testing protocol for fool-proof deployment, and build adaptive systems.

Before we start,
I have put up two of my most loved GTM systems “LinkedIn Profile Upgrade for 8x Visibility: AI Thought Leadership Transformation System”, “The Thought Leadership System: Build B2B Authority in 30 Days” on heavy discount... especially for you guys.
Checkout on the links below for the offers.
LinkedIn Profile Upgrade for 8x Visibility: AI Thought Leadership Transformation System
The Thought Leadership System: Build B2B Authority in 30 Days
You’re About to Master Custom GPTs and Claude Projects below…
7-Step Production Architecture - Complete blueprint from brainstorm to self-improving meta-instructions that 95% of operators skip, causing their CustomGPTs and Claude Projects to fail.
Deterministic Output Engineering - Five battle-tested techniques that eliminate 70% of regeneration cycles and achieve 95%+ format compliance
The Testing Protocol That Prevents Deployment Disasters - 10-point validation checklist that catches edge cases, ensures consistency, and guarantees 85%+ similarity across executions.
Self-Improvement Systems - Weekly evolution protocol that transforms static AI tools into systems that get 29% better over 6 months without manual intervention
Reverse Engineering any CustomGPT - Learn from the best ones out there.
If you’re paying $20/month for ChatGPT Plus or Claude Pro and not extracting $2,500+ in monthly value, you’re using these tools wrong.
Most operators just copy-paste incomplete instructions into a CustomGPT or Claude Projects, get inconsistent outputs, and blame the AI.
The real problem is not AI, but no systematic process.
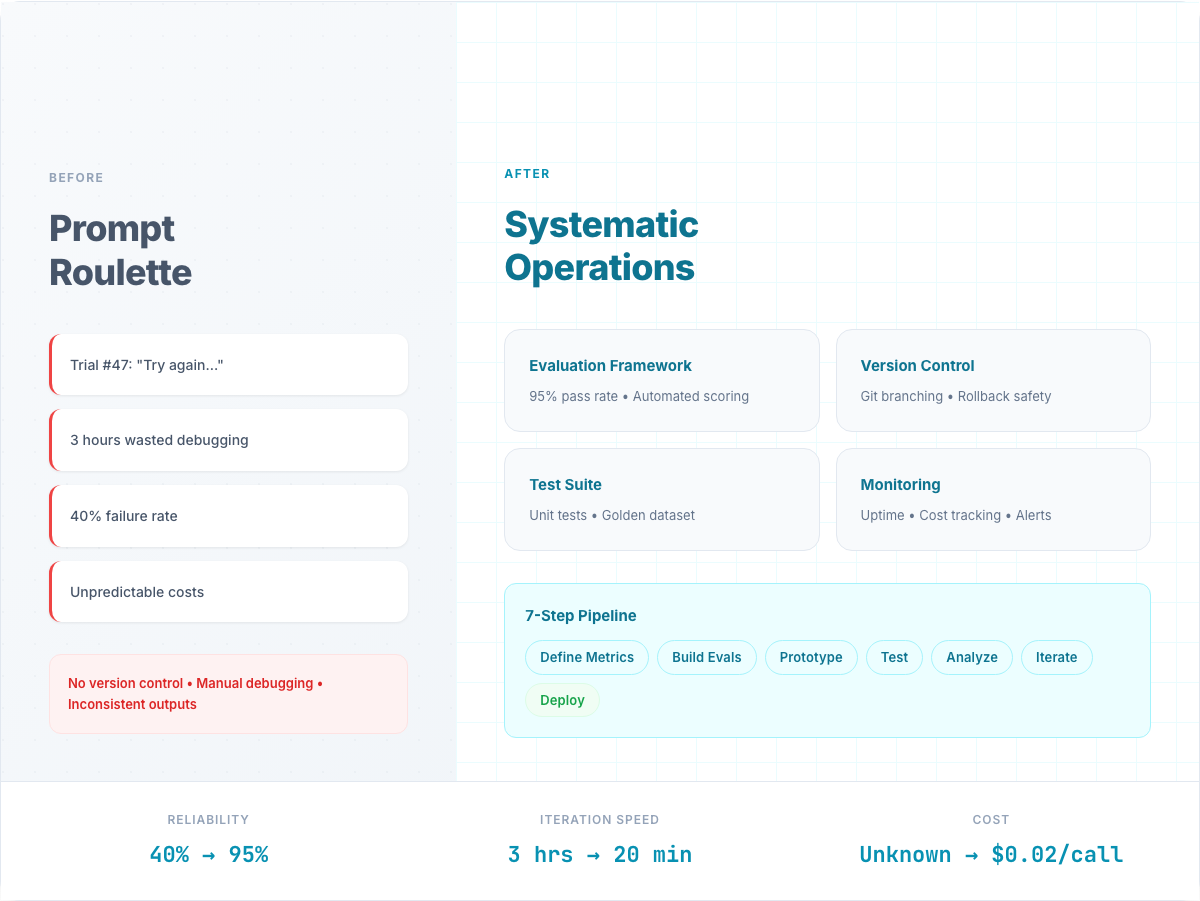
This guide gives you the exact 7-step framework to build CustomGPTs and Claude Projects that deliver deterministic outputs, handle edge cases, and improve themselves over time.
Let’s start with the foundation.
Step 1: The Brainstorm-to-Blueprint Process
Stop building before you think.
Most failed CustomGPTs start with operators jumping straight to instructions without mapping the workflow.
The 4-Phase Blueprint Process
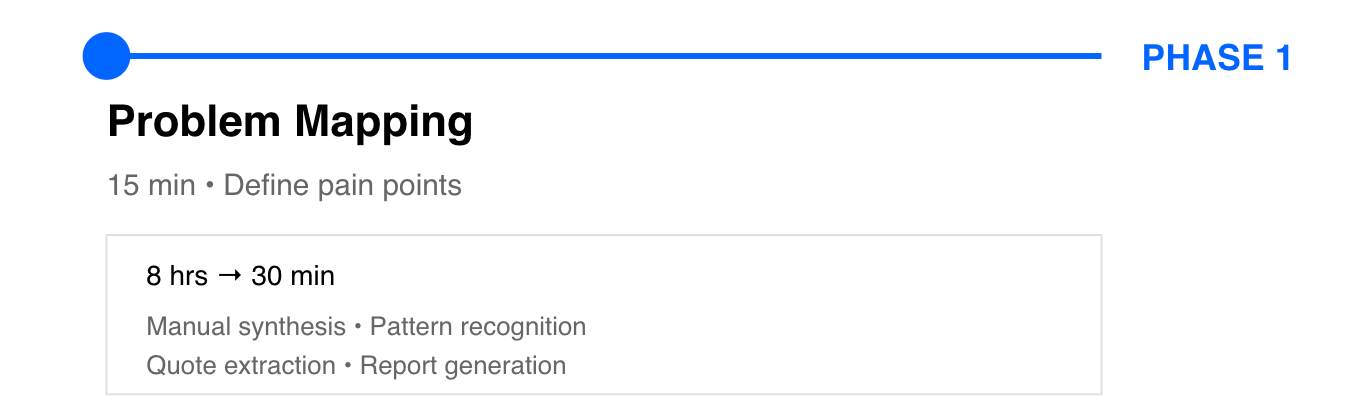
Phase 1: Problem Mapping (15 minutes)
Pick a high-frequency, high-pain workflow. Use this framework:
Problem Definition:
Current manual process: [Describe step-by-step]
Time per execution: [X hours]
Pain points: [Where does it break?]
Desired outcome: [What success looks like]
Frequency: [How often needed?]
Example: Customer Research Synthesis
Current process: Read 10 interview transcripts, extract quotes, identify patterns, write synthesis report
Time: 8 hours per project
Pain points: Inconsistent quality, slow pattern recognition, manual quote extraction
Desired outcome: Structured 1000-word report with patterns, quotes, recommendations in 30 minutes
Frequency: 4x per month
Phase 2: Workflow Prototyping (30 minutes)
Have an initial conversation with ChatGPT/Claude to solve the problem manually:
Prompt:
“I have 10 customer interview transcripts. Help me:
1. Extract verbatim quotes about pain points
2. Identify patterns across interviews
3. Generate actionable recommendations
Walk me through this step-by-step.”
Document what works and what fails. Note:
Which questions clarified ambiguity
What output format was most useful
Where the AI needed more context
What validation you had to do manually

Phase 3: Refinement Through Iteration (1-2 hours)
Run 3-5 test scenarios, progressively refining your approach:
Iteration 1: Basic request → Note gaps in output
Iteration 2: Add constraints (word count, format) → Test consistency
Iteration 3: Add examples → Measure quality improvement
Iteration 4: Add validation rules → Reduce manual editing
Iteration 5: Test edge cases → Ensure robustness
Track metrics:
Output quality score (1-10)
Format compliance (yes/no)
Time to acceptable output
Manual edits required
Phase 4: Instruction Generation (1 hour)
Now use AI to formalize your refined process:
Prompt:
“Based on this refined workflow [paste your process], create production-ready instructions for a CustomGPT that:
ROLE: Customer research analyst applying systematic methodology
OBJECTIVE: Transform interview transcripts into structured insights
CONSTRAINTS:
- Exactly 1000 words output (±20)
- 5 required sections with specific formats
- All claims must cite specific interviews
OUTPUT FORMAT: [Detailed template]
VALIDATION: [Quality gates before returning]
Include:
1. Complete instruction set
2. Required knowledge file structures
3. Validation checklist
4. Edge case handling protocols”This generates your foundation instruction architecture.
Step 2: Workflow Architecture - Choose the Right Model
The biggest mistake: wrong architecture for the task.
Here’s how to choose:
Decision Framework
Single-Step Workflows (30-60 min to build)
When to use:
One clear input → one transformation → one output
No branching logic needed
Same process every time
Examples: Meeting notes → status update, transcript → summary, raw data → formatted report
Structure:
INPUT: [Specific format]
PROCESS: [Single transformation with exact rules]
OUTPUT: [Structured template]
VALIDATE: [Self-check before returning]
Multi-Step Workflows (3-4 hours to build)
When to use:
Complex process requiring distinct phases
Quality gates between steps needed
Different AI capabilities per phase
Examples: Research synthesis (extract → classify → analyze → recommend), competitive analysis (identify → research → analyze → create battle cards)
Structure:
PHASE 1: [Task] → [Output] → [Checkpoint]
IF passes: PROCEED
IF fails: [Error handling]
PHASE 2: [Use Phase 1 output] → [Output] → [Checkpoint]
[Continue through phases...]
FINAL: [Synthesis] → [Complete output] → [Validation]
Broader Use-Case Agents (2-3 hours to build)
When to use:
Multiple related tasks under one umbrella
Input variety requires flexible routing
Team needs “assistant” not “specialized tool”
Examples: Marketing assistant (social posts, emails, briefs, analysis), operations assistant (documentation, coordination, analysis)
Structure:
INPUT CLASSIFICATION: Analyze request type
ROUTE to sub-protocol:
- IF [content creation]: Apply content protocol
- IF [data analysis]: Apply analysis protocol
- IF [research]: Apply research protocol
EXECUTE with domain knowledge
VALIDATE against use case
RETURN with confidence level
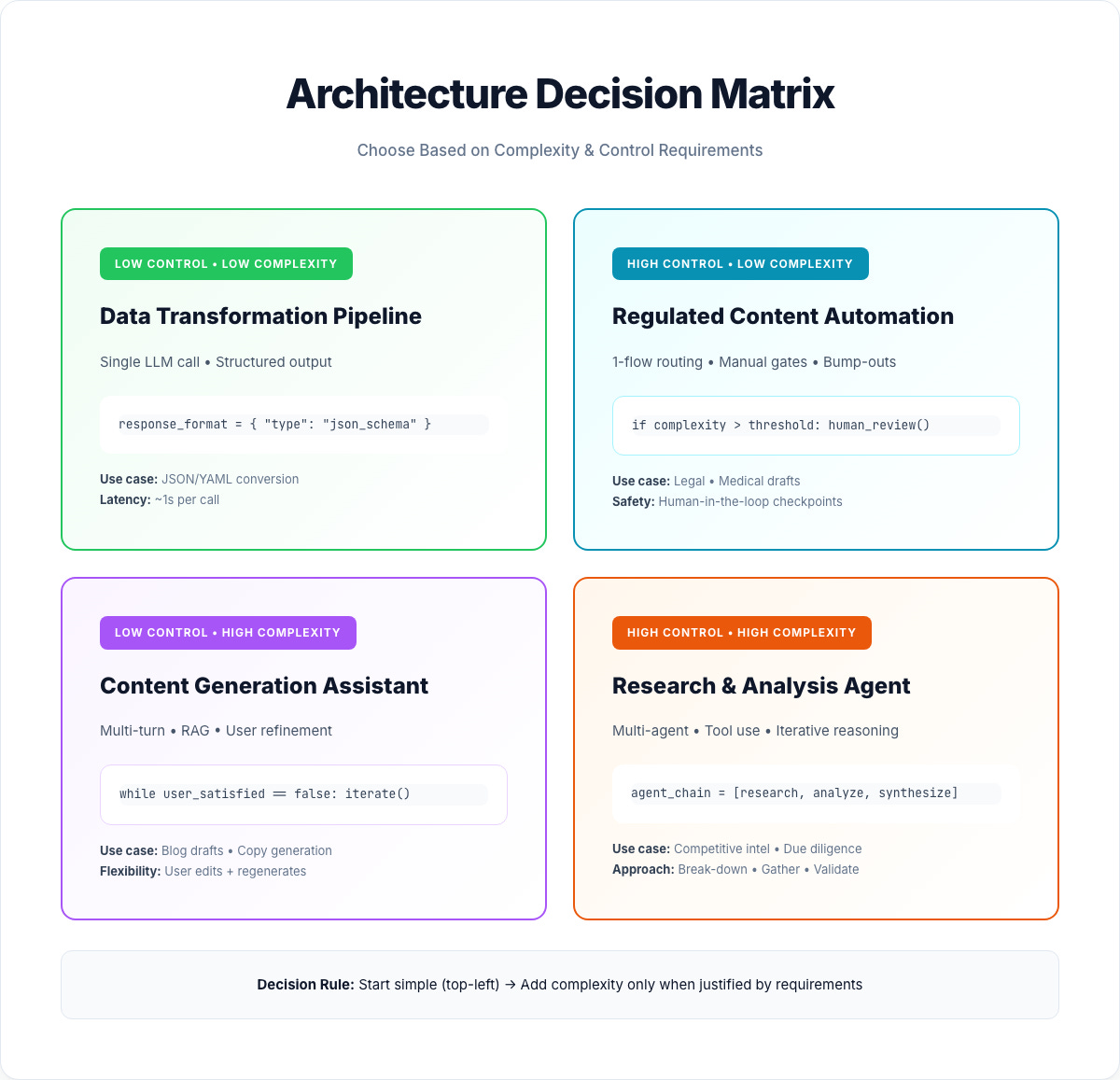
The 3-Question Decision Tree
Q1: Single repeatable transformation? → Single-Step Workflow
Q2: Requires sequential phases with quality gates? → Multi-Step Workflow
Q3: Need flexibility across varied tasks? → Broader Use-Case Agent
Step 3: The 10-Point Testing Protocol
Never deploy untested.
Here’s your validation checklist:
Pre-Deployment Tests (2-3 hours)
Test 1: Happy Path (3 perfect scenarios)
Verify all formatting rules followed
Check validation gates trigger correctly
Confirm output meets quality standards
Test 2: Edge Cases (3 scenarios)
Missing data: Does it ask for clarification?
Unusual input: Does it adapt gracefully?
Ambiguous request: Does it request specifics?
Test 3: Failure Modes (2 scenarios)
Contradictory requirements: Does it flag conflicts?
Impossible constraints: Does it explain limitations?
Test 4: Format Compliance (5 executions)
Target: 90%+ exact format match
Measure word count accuracy (±5%)
Verify all required sections present
Test 5: Knowledge Retrieval (10 queries)
Ask questions you know answers to
Verify correct information retrieved
Check source citations accurate
Test 6: Consistency (Same input 3x)
Should produce substantially similar outputs
Measure similarity score
Target: 85%+ consistency
Test 7: Cross-Reference Integrity
All mentioned files exist
Links work correctly
No contradictory information
Test 8: Speed (5 executions)
Average time to completion
Target: <manual process time
Test 9: Self-Correction
Trigger validation failures intentionally
Verify it catches and fixes issues
Test 10: User Acceptance (3 team members)
Real scenarios, 5 executions each
Collect quality scores
Target: 7.5+ average, 80%+ adoption intent

The Reset Mechanism for Exhaustive Workflows
For complex multi-step processes, prevent step-skipping with explicit reset triggers:
Instructions to add:
EXECUTION RESET PROTOCOL:
After completing each major phase, execute reset:
RESET_CHECKPOINT:
1. Summarize phase just completed
2. Confirm all required outputs generated
3. List any issues encountered
4. State next phase explicitly
5. Request user confirmation before proceeding
IF exhaustion detected (token limit approaching):
- STOP current execution
- SAVE progress to memory
- NOTIFY user of stopping point
- PROVIDE resume instructionsStep 4: Deterministic Outputs - Eliminate Regeneration Cycles
70% of regenerations are preventable.
Five techniques to ensure consistency:
Technique 1: Structured Output Formats
Instead of: “Summarize this research”
Use:
{
“executive_summary”: “3-5 sentences, 100-150 words”,
“key_findings”: [
“finding_1: 80 words with specific quote citation”,
“finding_2: 80 words with specific quote citation”,
“finding_3: 80 words with specific quote citation”
],
“recommendations”: [
“action_1: specific next step with expected outcome”,
“action_2: specific next step with expected outcome”
],
“total_word_count”: “950-1050 words”
}
Technique 2: Explicit Constraints
Bad: “About 800 words”
Good: “Exactly 800 words (±10 maximum). If you generate 850, trim to exactly 800 before returning.”
Add constraints for:
Length (precise ranges)
Structure (exact sections required)
Format (markdown, JSON, YAML)
Tone (professional, conversational, technical)
Required elements (must include X, Y, Z)
Technique 3: Built-In Validation
BEFORE RETURNING OUTPUT:
Step 1: Verify word count in target range
Step 2: Verify all required sections present
Step 3: Verify each section meets length requirements
Step 4: Verify all claims have source citations
Step 5: Verify no [TBD] or placeholder text
IF any validation fails:
- Regenerate to fix issues
- Do NOT return failing output
- Log which validation failed for review

Technique 4: Few-Shot Examples
Show the AI 2-3 examples of perfect outputs:
Generate customer testimonial in this exact style:
EXAMPLE 1:
“We reduced churn by 35% in 90 days using [Product].
The systematic approach made all the difference.”
- Sarah Chen, VP Customer Success, TechCo
EXAMPLE 2:
“ROI was 12x in year one. We saved 40 hours/month
on previously manual processes.”
- James Park, Head of Operations, ScaleCo
Now generate for [NEW_CUSTOMER] matching this pattern.
Technique 5: Constraint-Based Generation
Generate report following these constraints:
ABSOLUTE REQUIREMENTS:
- Word count: 980-1020 (must be in range)
- Sections: Exactly 5 with H2 headings
- Each section: 180-220 words
- Bullet points: 3-5 per section, each 30-50 words
- Citations: Minimum 1 per section in [Author, Year] format
VALIDATION:
Count sections: Should = 5
Count total words: Should = 980-1020
Count citations: Should >= 5
Check structure: H2 headings present
Result: Format compliance improves from 40% to 95%+.

Step 5: Review-Refinement Process with Self-Improvement
Build systems that get better over time.
Add these meta-instructions:
The Weekly Evolution Protocol
SELF-IMPROVEMENT SYSTEM:
After every 10 executions, automatically:
STEP 1: PERFORMANCE ANALYSIS
- Calculate average quality score (from user ratings)
- Identify most common user edits
- Detect failure patterns (what’s breaking repeatedly)
- Measure time-to-acceptable-output
STEP 2: PATTERN RECOGNITION
- What do 9+/10 outputs have in common?
- What causes <7/10 outputs?
- Which edge cases appeared 3+ times?
- Which validation gates catch most issues?
STEP 3: IMPROVEMENT PROPOSAL
Generate specific instruction updates:
- “ADD requirement: [Specific constraint based on pattern]”
- “TIGHTEN: [Specific rule that’s too loose]”
- “NEW VALIDATION: [Check for newly discovered failure mode]”
STEP 4: A/B TEST
- Propose specific instruction change
- Request human approval
- Test on next 5 executions
- Compare quality: New vs. Old
- Keep improvement if quality increases
STEP 5: KNOWLEDGE BASE UPDATES
- Add new examples from high-performing outputs
- Document new edge cases in failure_modes.md
- Update best_practices.md with learnings
- Expand taxonomy/frameworks as patterns emerge
Example: Evolving Research Synthesis Instructions
Week 1 Pattern: All 9+ outputs included specific customer examples
Action: Add requirement: “MUST include minimum 2 customer examples with company name, metric improved, and timeframe”
Week 4 Pattern: 3 failures due to missing competitive data
Action: Update competitive_landscape.md, add validation: “IF competitor data not found, flag for human review”
Week 8 Pattern: New edge case - company names with special characters cause parsing errors
Action: Add preprocessing: “BEFORE analysis, normalize company names: remove special characters, standardize spacing”
Result: Quality score improves 7.2 → 9.3 over 6 months (29% improvement).
Step 6: Meta-Instructions for Adaptive Systems
Instructions that modify behavior based on input.
This is advanced leverage:
The Conditional Logic Framework
META-INSTRUCTION ARCHITECTURE:
STEP 1: INPUT CLASSIFICATION (automatic)
Analyze request for:
- Audience type: technical / business / executive
- Complexity level: simple / moderate / complex
- Urgency: rush / standard / thorough
- Quality requirement: draft / review-ready / publication
STEP 2: ADAPTIVE ROUTING
IF audience == “technical” AND complexity == “complex”:
→ Use detailed technical template
→ 800-1000 words acceptable
→ Technical jargon encouraged
→ Include architecture diagrams
ELSE IF audience == “executive” AND urgency == “rush”:
→ Use executive summary template
→ Maximum 300 words
→ No technical details unless critical
→ Lead with business impact
[Continue for all relevant combinations...]
STEP 3: SELF-CHECK
Before returning:
- Did I correctly identify audience?
→ IF uncertain: Ask clarifying question
- Does output length match urgency?
→ Rush: <500 words, Thorough: 1000-2000 words
- Is technical depth appropriate?
→ Verify against audience type
IF any check fails: Regenerate before returning
Real Example: Adaptive Sales Objection Handler
OBJECTION CLASSIFICATION (automatic):
Scan for keywords:
- “price”, “expensive”, “budget” → pricing_objection
- Competitor name → competitive_objection
- “don’t have”, “missing” → feature_gap_objection
- “not now”, “later” → timing_objection
ROUTE TO RESPONSE TEMPLATE:
- pricing_objection → ROI framework + value justification
- competitive_objection → Battle card + customer switch story
- feature_gap_objection → Workaround OR roadmap commitment
- timing_objection → Risk of delay + incentive
CUSTOMIZE RESPONSE:
- Pull relevant proof point from knowledge base
- Match to prospect’s industry
- Include specific metrics
SELF-CHECK:
- Does response address exact objection?
- Is proof point relevant to prospect?
- Is CTA clear and specific?
Result: 85%+ appropriate responses without manual routing.

Step 7: Reverse Engineering Success
Don’t build from scratch. Learn from proven systems.
The goal is to identify techniques that you can copy:
Specific phrasing that works (”You MUST”, “BEFORE returning”, “IF validation fails”)
Validation gate structures
Knowledge file templates
Output format schemas
Self-checking logic
Don’t copy: Use case-specific content (their examples, their data)
Do copy: Systematic patterns (how they structure, how they validate)
Two Ways of Reverse Engineering
First - Copy the following into any “CustomGPT”
Template for analysis:
## System Analysis: [CustomGPT Name]
**Use Case**: [What it does]
**Architecture**: [Single/Multi-step/Broader agent]
**Instruction Patterns Identified**:
1. Role definition: [Specific expertise claimed]
2. Constraints: [What boundaries set]
3. Output format: [Structured how]
4. Validation: [Quality checks present?]
**Knowledge Architecture**:
- File count: [Number]
- Organization: [Folder structure]
- Update frequency: [Static/Dynamic]
- Cross-referencing: [How files link]
**What Makes This Work**:
- Key insight 1: [Specific technique]
- Key insight 2: [Specific technique]
- Key insight 3: [Specific technique]
**Adaptable Patterns for My Use Case**:
- Pattern 1 → Apply to [my workflow]
- Pattern 2 → Adapt for [my context]Which step transformed your CustomGPT from inconsistent to production-ready? Drop your biggest win in the comments.
Second - Ask following questions to reverse engineer step by step
STEP 1 – Identify Reference System
Purpose: Understand what the target GPT is, who it serves, and what success patterns exist.
Question Guidelines:
What is the primary use case and ICP this system serves?
How do users describe its value proposition in reviews or listings?
Which category or function does it belong to (e.g., writing, marketing, analysis, workflows)?
What is the core differentiator visible in its description or ratings?
How does it frame its outcomes (speed, precision, personalization, etc.)?
What signals suggest systematic design or modularity?
Which similar systems exist – and how does this one position itself against them?
What metrics (rating, reviews, installs) indicate its traction and validation?
Advanced Layer:
What psychological hooks or trust triggers are embedded in its title, thumbnail, or tagline?
What hidden patterns make it stand out in its category?
STEP 2 – Deconstruct Architecture
Purpose: Reveal how the system is structured internally (prompt logic, flows, sub-agents, memory layers, gating systems).
Question Guidelines:
What is the architecture type (single prompt, modular, multi-step agentic)?
Does it rely on user inputs or internal context scaffolding?
What are the instructional segments (system, meta, contextual, evaluative)?
What is the data flow between steps?
Are there visible signs of looping logic, feedback, or dynamic branching?
How are outputs evaluated or refined (quality gates, scoring, reasoning chains)?
How does it handle state or memory persistence?
What roles or agents seem to exist (Strategist, Editor, Evaluator, etc.)?
Advanced Layer:
Can you infer prompt hierarchy (root → sub-module → action layer)?
What patterns of self-reflection or “meta-instructions” does it appear to use?
STEP 3 – Decode Prompt Design & Meta-Instructions
Purpose: Extract how the prompts are structured, layered, and governed by meta-instructions.
Question Guidelines:
How are roles and instructions defined (e.g., “You are an expert in…”)?
Does it include thinking framework cues (Tree of Thought, Chain of Thought, etc.)?
How does it enforce quality control (rubrics, gates, scores)?
What variables or placeholders are used for customization?
How are examples or few-shots integrated?
What tone, constraints, or formatting rules are embedded?
How are multi-step instructions sequenced or nested?
How does the system handle ambiguity or clarification loops?
Advanced Layer:
What meta-thinking or instruction-about-instructions patterns can you identify?
Which hidden directives ensure consistent personality or voice across runs?
STEP 4 – Extract Knowledge Model & Data Context
Purpose: Determine what knowledge, files, or data context the GPT depends on – and how it structures or retrieves them.
Question Guidelines:
Does it reference any internal knowledge files, glossaries, or frameworks?
What types of context blocks are likely stored (persona, ICP, playbooks)?
How does it blend static + dynamic data?
Are there signs of tool integrations or APIs (Google, Supabase, etc.)?
How is contextual continuity maintained (memory, embeddings, etc.)?
How does it ensure relevance and recency?
What kind of taxonomy or hierarchy exists across its context layers?
Advanced Layer:
Can you deduce a Knowledge Architecture Diagram (e.g., Core → Peripheral → Live Context)?
How might this model map to Revenoid’s or StartupGTM’s knowledge-file ecosystem?
STEP 5 – Infer Differentiators, Experience Layer & Replication Blueprint
Purpose: Synthesize all patterns into a replication-ready insight base – what to replicate, what to innovate.
Question Guidelines:
What UX or conversational patterns make it engaging?
How does it drive trust and flow?
What elements create personalization (naming, adaptive tone, data referencing)?
How does it deliver progressive depth or “aha moments” to the user?
What system differentiators (gates, quality checks, instruction layers) contribute to its 10x output?
What replicable frameworks could you extract?
What are non-replicable magic elements (proprietary logic, human-in-loop insight)?
Advanced Layer:
What would be the blueprint summary of this system (inputs → process → outputs → differentiators)?
If you were to rebuild this GPT, what sequence of steps would you follow to achieve functional parity?
Optional: Post-Processing Instructions (for CustomGPT itself)
Once the user answers all the above, instruct the CustomGPT to:
Generate a System Map (architecture + instruction hierarchy)
Extract Prompt Templates (annotated structure)
Build a Knowledge Context Inventory
Identify Differentiation Zones (what makes it special)
Output a Rebuild Blueprint (ready for Lovable/Claude/GitHub implementation)
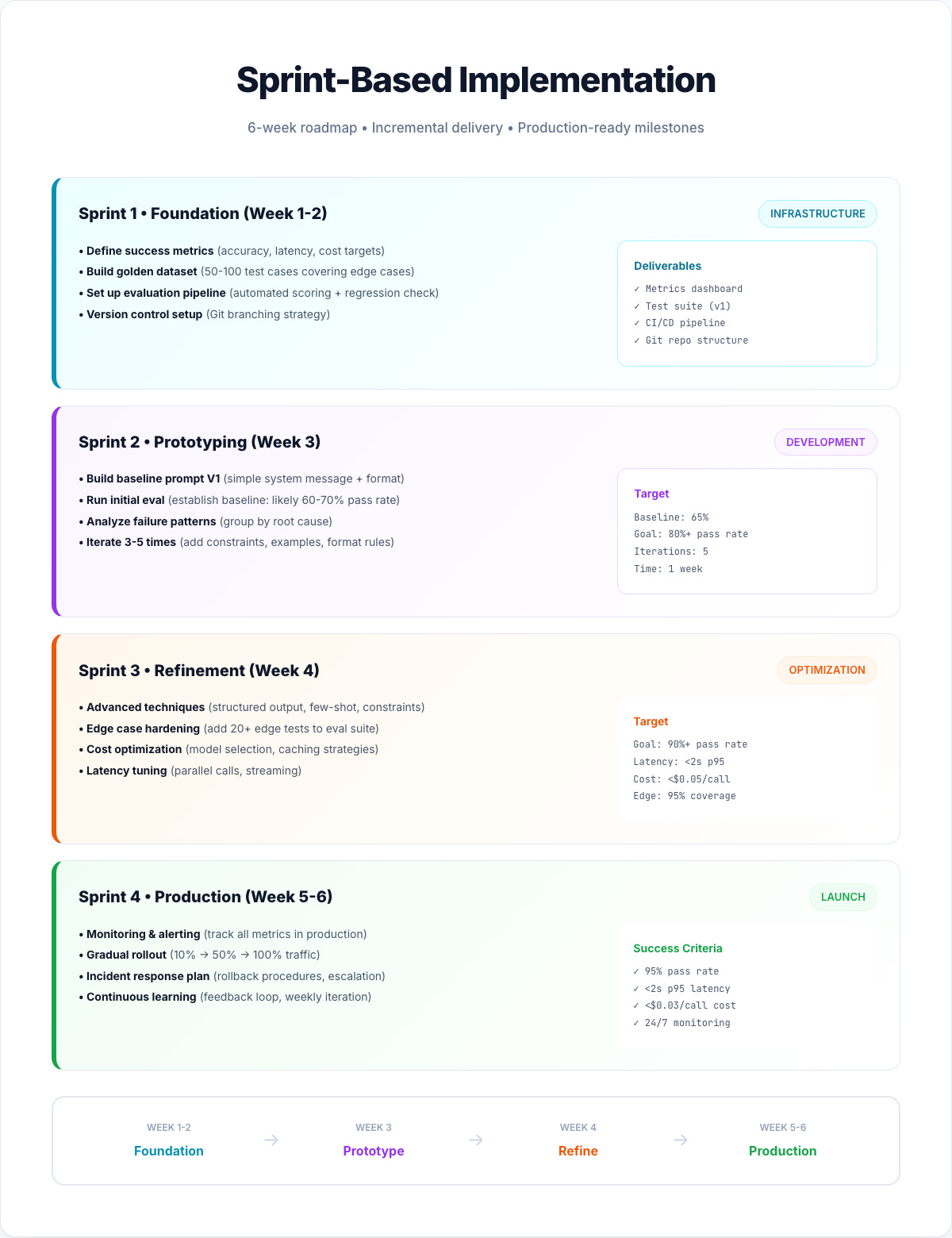
Your 48-Hour Quick Start
Day 1 (4 hours):
Pick one high-frequency workflow
Run brainstorm-to-blueprint process (Step 1)
Choose architecture type (Step 2)
Generate initial instructions
Day 2 (4 hours):
Build knowledge files
Run 10-point testing protocol (Step 3)
Implement deterministic output techniques (Step 4)
Deploy and start tracking
Week 1-2: Monitor and apply review-refinement (Step 5)
Month 1: Add meta-instructions for adaptation (Step 6)
Ongoing: Reverse engineer improvements from successful systems (Step 7)
Expected ROI:
Setup: 8-12 hours
Time saved per execution: 50-70%
Monthly value: $2,000-$5,000
Payback: 1-2 weeks
The Unlock
The operators who win aren’t waiting for GPT-5.
They’re mastering the systematic process to build AI systems that work reliably today.
You now have the complete blueprint:
brainstorm-to-blueprint workflows,
architecture selection frameworks,
testing protocols that catch failures before deployment,
deterministic output techniques eliminating regeneration cycles,
self-improving systems that evolve automatically,
adaptive meta-instructions,
and reverse engineering methodologies.
Start with one workflow. Apply the process. Measure the impact.
The $2,500+ monthly value is waiting.
Build systems. Not prompts.
Loved this post?
And subscribe to “Prompts Daily Newsletter” as well…
If you’re not a subscriber, here’s what you missed earlier:
5 LinkedIn Systems Generating 8-Figure B2B Pipelines [Complete Teardown]
Distribution Before Product: The Operator’s 90-Day GTM Playbook - With Prompts
Nathan Latka SaaS Playbook - 34 Growth Tactics, 15 Growth Hacks and AI Prompts (Part 1 of 2)
The Lenny Rachitsky Playbook : Prompts, Growth Frameworks, and Strategies - Part 1 of 2
Subscribe to get access to the latest marketing, strategy and go-to-market techniques . Follow me on Linkedin and Twitter.
